CPU Scheduling이란, 어떤 Task를 CPU에 할당할지 결정하는 것을 의미한다.
CPU Schedular는 어떤 기준 혹은 순서로 CPU를 할당할지에 대한 "정책"을 가지고 Task를 CPU에 할당하게 된다.
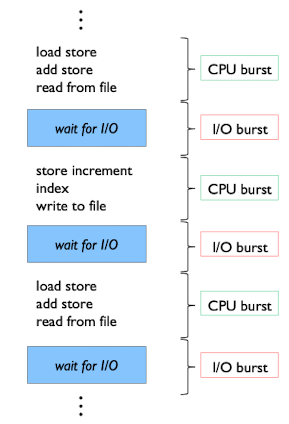
CPU - I/O Burst Cycle
Process는 다음과 같이 I/O Burst와 CPU Burst의 사이클로 반복된다.
- I/O Burst : I/O(입출력)를 위한 대기 시간 (Process는 wait상태가 된다)
- CPU Burst : CPU를 사용하는 시간
"I/O Burst Job"는
CPU를 짧게 쓰고 중간에 I/O Burst가 끼어드는 경우가 많은 작업이다.
즉, CPU Burst가 짧은 Job을 의미한다.
보통 유저와 상호작용하는 프로그램이 여기에 속한다.
반면, "CPU Bound Job"의 경우는
CPU를 오랫동안 사용하며, I/O의 빈도가 적은 작업을 의미한다.
즉, CPU Burst가 긴 Job을 의미한다.
계산 위주의 프로그램이 여기에 속한다.
PC환경에서 I/Bound Job과 CPU Bound Job이 섞여 있기 때문에,
CPU Bound Job이 CPU를 너무 오래 점유하고 있게 되면,
유저와 상호작용해야 하는 I/O Bound Job이 수행되지 못하는 상태가 된다.
따라서, 적절한 CPU Scheduling을 통해 이를 적절히 조절해주어야 한다.
CPU Scheduler
CPU는 idle(쉬고 있는) 상태라면, OS는 Ready Queue에 있는 Process 중 하나를 선택해 실행한다.
이때, 실행할 Process를 선택하는 것은 CPU Schedular( Short-term Schedular )가 담당한다.
Preemptive vs. Non-Preemptive
Preemptive Scheduling이란,
어떤 Task가 정상적으로 수행되는 도중에, 다른 Task가 CPU를 강제로 점유하여 실행할 수 있는 Scheduling을 의미한다.
Preemptive Scheduling은 다음과 같은 상황에서 스케쥴링을 진행한다.
- Process가 running에서 ready state로 전환될 때 (timer interrupt)
- wait state에서 ready state로 전환될 때 (I/O 완료)
반면, Non-Preemptive Scheduling이란,
한 Task가 CPU를 점유하고 있다면, Task가 종료되거나 I/O로 wait상태로 되기 전까진 다른 Task가 CPU를 점유할 수 없다.
Non-Preemptive Scheduling은 다음과 같은 상황에서 스케쥴링을 진행한다.
- Running State에서 wait state로 전환될 때
- 프로세스가 종료될 때
위와 같은 상황에서, 해당 Task는 CPU의 필요가 없게 되므로 CPU 제어권을 다른 Task에게 넘겨주게 된다.
즉, Preemptive Scheduling은 OS가 강제로 Task의 CPU사용권을 통제하는 방식이고,
Non-Preemptive Scheduling는 Task가 스스로 CPU의 사용권을 다른 Task에게 넘겨주는 방식이다.
Dispatcher
CPU Schedular가 다음에 수행할 Process를 결정하면,
Dispatcher는 선택된 Process에게 CPU Control을 할당한다.
Dispatcher가 하는일은 다음과 같다.
- Switch Context
- User Mode로 변환
- 수행될 Process의 시작될 위치를 찾아 jump 한다.
즉, Dispatcher는 Context Switching을 통해 작업을 교체하고
새로운 작업이 시작될 수 있도록 세팅한다.
이렇게 걸리는 시간을 "Dispatch Latency"라 부른다.
Scheduling Criteria(기준)
- CPU utilization : CPU를 가능한 바쁘게 유지시키는 것은 중요한 기준이 된다.
- Throughput : 단위 시간당 완료된 프로세스의 개수를 의미한다.
- Thurnaround time(총처리 시간) : Task의 처음부터 끝까지를 의미한다. (ready queue에 들어와서 CPU실행 + I/O 실행)
- Wating time : Ready Queue에서 대기하면서 보낸 시간의 합이다.
- Response time : Ready Queue에 들어간 후로부터 처음 작업이 수행되기(처음 Response)까지 시간이다.
CPU Scheduling Algorithm을 설계하기 위해서,
CPU utilization, Throuput은 maximize해야 하고,
나머지는 minimize해야 한다.
특히나, User와 interation이 많은 interactive system의 경우 response time을 최소화하는 것이 중요하다.
CPU Scheduling Algorithm (Single-Processor)
FCFS (First Come First Service)
가장 간단한 CPU Scheduling Algorithm으로,
CPU에 가장 먼저 요청한 Task가 가장 먼저 CPU를 할당받는 방식이다.
해당 알고르짐은 Non-Preemptive 방식이다.

Process가 P1, P2, P3순으로 들어왔다고 가정하고, CPU Burst time은 위와 같다고 가정하자.

각 프로세스 P1은 0, P2는 24, P3는 27의 waiting time을 가지게 된다.
따라서, 평균 waiting time은 17이 된다.
FIFO Queue로 쉽게 구현할 수 있지만,
Average Waiting Time이 길어질 수 있다는 단점이 있으며,
SJF & SRT
SJF와 SRT는 가장 작은 CPU Burst의 Task를 CPU에 할당하는 방식이다.
SJF는 Non-Preemptive Scheduling 방식인 반면,
SRT는 Preemptive Scheduling 방식이다.
SJF (Shortest Job First)
가장 작은 CPU Burst의 Task를 CPU에 할당하는 방식이며,
Non-Preemptive Shceduling 방식이다.

arrival time은 ready Queue에 Process가 들어온 시간을 의미한다.

P1이 먼저 들어오며, ready Queue에 P1밖에 없으므로 P1이 우선적으로 실행되며,
Non-Preemptive이기 때문에 7초 동안 CPU를 점유하게 된다.
P1의 수행이 종료될 시점에 Ready Queue에는 P2, P3, P4의 process가 위치하게 된다.
이때, Burst time은 P3가 가장 작으므로 P3가 실행된다.
각 P1는 0, P2는 6, P3는 3, P4는 7의 waiting time을 가지게 된다.
따라서, 평균 waiting time은 4가 된다.
P1은 0, P2는 6, P3는 3, P4는 7의 waiting time을 가지며,
평균 waiting time은 4가 된다.
SRT (Shortest-Remaining-Time-Frist)
SRT 알고리즘은 SJF방식처럼 가장 작은 CPU Burst의 Task를 CPU에 할당하는 방식이지만,
Preemptive 방식이다.
따라서, ready Queue에 새롭게 추가된 Proess가
현재 수행되고 있는 Process보다 더 짧은 Burst time을 가졌다면 Process가 교체된다.
해당 경우엔, 수행되고 있는 Process는 running state에서 ready state로 된다.
만약, 현재 수행되고 있는 Process과 새로 들어온 Process의 CPU Burst time이 같다면,
Dispatch Latency때문에 수행하고 있던 Process를 그대로 수행한다.


처음에는 Ready Queue에 P1밖에 없으므로, P1이 수행이 된다.
P1이 수행되고 2초 후 P2가 ready queue에 들어오게 된다.
이때, P1의 남은 Burst time은 6초이고, P2의 CPU Burst time은 4초이기 때문에,
P1는 ready state로 변경되며, 다시 ready queue에 들어가게 된다.
P1의 CPU 제어권을 P2가 선점하게 된다.
P2가 수행되고 2초 후 P3가 ready Queue에 들어오게 된다.
Ready Queue에서 P1은 6, P2는 2, P3는 1의 CPU Burst time을 가지게 된다.
따라서, 가장 적은 CPU Burst time을 가진 P3로 CPU 제어권은 넘어가게 된다.
P3는 1초 후 수행을 완료하여 종료되고, P4가 Ready Queue 들어오게 된다.
Ready Queue에서 P1은 6, P2는 2, P4는 4의 CPU Burst time을 가지게 된다.
가장 적은 CPU Burst time을 가진 P2가 CPU제어권을 받게 되고 이후엔, P4, P1순으로 수행이 된다.
P1는 9, P2는 1, P3는 0, P4는 2의 waiting time을 가지며,
평균 waiting time은 3이 된다.
Exponential Averaging
SJF와 SRT는 평균 waiting time입장에선 최적(Optimal) 알고리즘이다.
하지만, CPU Burst time이 긴 Task는 계속 실행될 수 없는 Starvation 현상이 발생할 수 있다.
또한, CPU-I/O Burst Cycle에서 알 수 있듯이,
실제 Process는 I/O Burst와 CPU Burst가 섞여 있기 때문에,
실행하기 전까지 CPU Burst를 알아내기란 현실적으로 어려운 일이다.
따라서, CPU Burst time을 "Exponential Averaging"방식을 통해 예측하게 된다.
Exponential Averaging 방식은 이전 Task의 CPU Burst time을 기반으로 예측한다.

- $t_n$: $n^{th}$ Task의 actual CPU Burst time
- $\tau_n$: $n^{th}$ Task의 Predict한 CPU Burst time
- $\alpha$ : [0,1]의 범위를 가지며, 파라미터이다.
$\alpha$값이 0인 경우,
이전 Task의 Actucal CPU Burst time($t_n$)을 통해서만 예측을 한다는 것이고,
$\alpha$값이 1인 경우,
이전 Task의 Predict한 CPU Burst time($\tau_n$)을 통해서만 예측을 진행한다는 의미이다.
보통, 0.5의 값을 갖는다.
Priority Scheduling
각 Process에 정수의 우선순위를 부여하여,
우선순위가 높은 Process부터 실행하는 Scheduling Algorithm이다.
해당 방식은 Preemptive, Non-Preemptive 기법 둘 다 구현이 가능하다.
SJF, SRT도 하나의 Priority Scheduling인데,
Predicted CPU Burst time이 우선순위가 된다.
이러한, Priority Scheduling에선
우선순위가 낮은 작업은 절대 실행될 수 없는 "Starvation"현상이 생길 수 있다.
SJF, SRT 역시 Predicted CPU Burst time이 큰 작업은 계속 뒤로 밀리게 된다.
이는 시간이 지남에 따라 Priority를 올려주는 "Aging"기법을 통해서 해결할 수 있다.
Round Robin (RR)
Round Robin은 Multi-Tasking을 위해 설계되었으며,
Preemptive기법이다.
각 Process는 "time slice" 혹은 "time quantum"이라는 작은 단위의 시간을 할당받는다.
Process는 최대 time slice(quantum) 동안 CPU를 사용하며,
해당 시간이 지나면 OS에 의해 CPU 제어권을 다른 Process에 넘겨주고 ready queue에 추가된다.
Round Roubin에서의 ready queue는 원형 Queue이며, 추가되는 process는 tail에 추가된다.
만약 $n$개의 process가 ready queue에 존재하고, time quantum이 $q$라 가정하면,
어떤 process도 $(n-1)q$ 보다 오래 기다리지는 않는다.
만약 time slice($q$)가 큰 경우는 FCFS 방식이 되고,
time slice($q$)가 작은 경우, 잦은 context Switching으로 인한 오버헤드가 생기게 된다.

time slice 혹은 time quantum ($q$) 이 2라고 가정하자.

처음에 P1이 실행되고,
time slice($q$)가 2이고, CPU Burst time은 3이므로,
2초가 지나면 남은 CPU Burst time 1이 되어 ready queue에 추가된다.
후에, P2는 2, P3는 4의 남은 CPU Burst time으로 ready queue에 추가된다.
P4의 경우는 time slice 동안 Task를 완료할 수 있기 때문에,
작업을 완료하고 ready queue에 추가되지 않는다.
앞서 말했듯 Round Robin에서 ready Queue는 원형 큐이기 때문에,
P1, P2, P3순으로 실행된다.
또한, P1의 경우 남은 CPU Burst time이 1이었으므로,
1초가 실행되고 CPU 제어권을 돌려준다.
response time이란 Request를 보낸 후로부터 처음 Response가 시작되는 시간이다.
즉, ready queue에 들어가고 처음 수행되기 까지의 시간이다.
따라서, P1은 0, P2는 2, P3는 4, P4는 6의 response time을 갖게 되며
평균 response time은 3을 갖게 된다.
보통 SJF, SRT방식보다 평균 처리시간(turnaround time)은 길지만, 평균 response time 더 짧다.
Multilevel Queue
Multilevel queue는 ready queue를 여러 가지 queue로 나누며,
Task를 특성에 따라 분류하여, 특성에 맞는 queue로 들어간다.

또한, 각 queue는 별도의 Scheduling Algorithm을 갖는다.
예를 들어, foreground queue(interactive)는 RR, background queue(batch)는 FCFS를 사용하는 경우다.
Multilevel Queue에서는 queue들 간에도 Scheduling을 진행해야 한다.
대표적으로 "Fixed Priorty Scheduling"과 "Time Slice" 방식이 있다.
Fixed Priority Scheduling의 경우는 queue마다 우선순위를 할당하여 우선순위가 높은 queue의 process부터 실행한다.
Priority Shceduling 방식과 마찬가지로 starvation 현상이 발생할 수 있다.
Time Slice의 경우는 각 queue마다 Time Slice를 할당한다.
예를 들어 foreground queue에는 80%를 background queue에는 20%를 할당하는 방식이다.
Multilevel Feedback Queues
Multilevel Feedback Queue는 Multilevel Queue와 유사하다.
- ready queue가 여러 queue로 구성
- 각 queue는 Scheduling Algorithm 존재
Multilevel Queue에서는 process는 특성에 맞는 queue로만 들어갔다면,
Multilevel Feedback Queue에서는 process들이 다른 큐로 이동하는 것을 허용한다는 차이점이 존재한다.

Multilevel Feedback queue Scheduler는 추가적으로 아래의 경우도 고려해야 한다.
- 어떤 process를 상위 Queue로 보낼지, 어떤 Process를 하위 Queue로 보낼지
- 어떤 queue에 Process를 할당할지
Multilevel Queue에서 Fixed Priority Scheduling으로 queue들 간의 스케쥴링을 하게 되면,
starvation 현상이 발생할 수 있는데
Multilevel Feedback Queue는 다른 Queue로 보낼 수 있다는 점에서 일종의 Aging 방식의 하나로 볼 수 있다.
Multi-Processor Schduling
Multi-Processor에서의 Scheduling은 어떤 Processor에 어떤 Process를 할당할지,
각 Processor마다 얼마만큼 분배할지 등과 같은 동기화 이슈가 추가로 생기게 되어
Single-Processor의 Scheduling보다 복잡하다.
Multi-Processor에서의 Shceduling 방식은
"Asymmetric multiprocessing"와 "Symmetric multiprocessing(SMP)"로 나눌 수 있다.
"Asymmetric multiprocessing"은 Master Processor(CPU)가 모든 Scheduling을 결정한다.
즉, 어떤 Proccessor(CPU)에 어떤 Process를 할당할지 Master Processor가 결정하고,
나머지 Processor들은 이를 따른다.
또한, Master Processor에서만 I/O 작업과 같은 Kernel Code가 실행되고,
나머지 Processor에서는 User Code가 실행되기에 동기화 문제를 해결할 수 있다.
따라서, Master Processor에서 결정만 하고 배분하면 되기 때문에 ready queue는 하나만 존재한다.
"Symmetric multiprocessing(SMP)"은 각 Processor(CPU)가 어떤 Process를 할당할지 스스로 결정하며,
현대 가장 많이 사용하는 방식이다.
따라서, ready queue를 Processor끼리 공유할 수 있지만, 독자적으로 가질 수도 있다.
또한, Multi-Processor Scheduling에서는 효율적인 스케쥴링을 위해 "Processor affinity"와 "load balancing" 기법을 사용한다.
Processor Affinity
Processor Affinity(친화성)이란,
Process를 친숙한 Processor 할당하는 방식이다.
CPU내에는 Cache라는 메모리가 존재하며, 자주 쓰는 data를 Main Memory로부터 load하여 빠르게 접근할 수 있도록 해준다.
따라서, Affinity(친숙)한 Process는 특정 Processor(CPU)의 Cache memory에 data들이 있기에, 빠르게 접근할 수 있다.
즉, 성능이 좋아진다.
- Soft Affinity : 친숙한 Processor에 할당하려 노력하지만, 보장하지는 않는다.
- Hard Affinity : 친숙한 Processor에 할당할 것을 보장한다.
NUMA 시스템
각 Memory에는 개별 Bus를 통해 Processor와 연결되어 있으며,
Processor는 공용 Bus에서 전기적인 신호를 통해 Memory에서 데이터를 가져온다.
하지만, 공용 Bus에는 한 번에 하나의 Processor만이 점유할 수 있다.
따라서, Multi-Processor가 Shared Memory를 사용하게 된다면,
같은 Memory에 여러 Processor가 접근하는 경우에는
하나의 Processor만이 해당 Memory와 연결된 공용 Bus를 점유할 수 있기에,
다른 Processor에서 해당 Memory에 접근하지 못하게 되는 병목현상이 발생한다.
NUMA 시스템을 도입하여, 이를 해결한다.
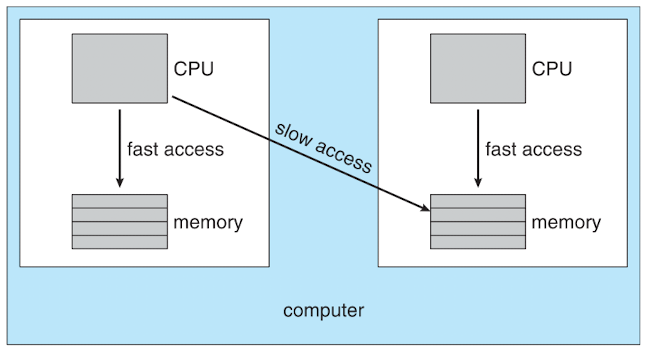
Processor와 Memory는 물리적인 위치의 존재하며,
이에 따라 가까운 Processor와 Memory는 Bus를 통해 데이터를 전달받는 속도가 빠르게 될 것이다.
각 Processor는 독립적인 Local memory 공간을 가지고 있으며,
Local Memory는 빠르게 접근할 수 있는 Memory로 구성된다.
이를 통해, 여러 Processor에서 Local Memory에 접근한다면 빠르게 접근도 가능하며,
병목현상도 발생하지 않는다.
Multi-Processor의 Scheduling에서는 특정 Memory에 접근을 자주 하는 Task라면,
빠르게 접근할 수 있는 Processor에 할당한다.
즉, 해당 Processor는 해당 Task를 빨리 처리할 수 있으므로,
Task에 Affinity(친숙)한 Processor에 할당했다고 볼 수 있다.
위와 같이 Memory 구조도 Affinity에 영향을 줄 수 있다.
Load Balancing
독자적인 Ready Queue를 가진 SMP의 경우
Processor의 효율을 높이기 위해,
한쪽 Processor에 작업이 몰리는 것이 아닌, Balance(균등)하게 분배한다.
Load Balancing에는 "Push migration"과 "Pull migration"가 있다.
Push migration은
특정 Task가 주기적으로 Processor의 상태를 체크하고,
Overload 된 Processor를 발견하게 되면, 다른 Processor로 Task를 옮긴다.
Pull migration은
idle(쉬고 있는) Processor는 바쁜 Processor로부터 Task를 가져온다.
Real Time Scheduling - Linux
Real Time System은
"Hard Real Time System"과 "Soft Real Time System"으로 구분할 수 있다.
"Hard Real Time System"은 Task를 반드시 deadline(마감시간)까지 끝나는 것을 보장한다.
반면, "Soft Real Time System"은 Task가 deadline(마감시간)까지 보장하지는 않지만, deadline까지 끝낼려고 노력한다.
Linux의 경우 Soft Real Time System인데,
높은 우선순위의 작업은 먼저 실행되며, 더 많은 time slice를 갖는다.
또한, 모든 Process의 time slice가 0이라면, time slice를 재계산한다.

Algorithm Evaluation
Scheduling Algorithm을 평가할 수 있는 방법 4가지에 대해 알아보자.
Deterministic Modeling
Deterministic Modeling은 이론적인 방법으로 다음과 같다.
우선, workload를 다음과 같이 사전에 정의한다.
해당 workload를 토대로, 각 Scheduling Algorithm을 적용하여, Performance를 측정한다.
예를 들어 Round Robin의 경우 아래와 같이 진행되며 (time slice = 2), 평균 response time은 3을 갖게 된다.
이러한 방법은, 이론적인 방법이기 때문에 간단하며 빠르다.
Queueing Models
Queueing Model 역시 이론적인 방법으로,
CPU Burst와 I/O Burst의 확률분포를 측정하여,
확률 분포로부터 특정 수학적인 formular를 이용하여 performance를 측정한다.

위와 같이 Task가 Queue에 들어오는 "Arrival rate"와
CPU나 I/O에서 Task가 처리되는 "Servcie rate"를 알 수 있다면,
utilization, 평균 queue length, 평균 waiting time을 계산할 수 있다.
하지만, 분석할 수 있는 경우가 제한적이다.
Simulation
이는, 이론적이 아닌 직접 해보는 평가 방식이다.
Process의 갯수, CPU Burst time 등등을
특정 확률 분포를 기반으로 랜덤하게 샘플링한다.

이를 통해서 Simulation(모의 실험)을 진행하는 방식이며,
앞선 이론적인 방법들보다 정확도가 좋다.
Implementation
직접 구현하여 평가해 보는 방식이며, 가장 정확하지만 Cost가 비싼 방식이다.
Reference
Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 9th』
'CS > Operating System' 카테고리의 다른 글
| [OS] DeadLock (1) | 2023.04.29 |
|---|---|
| [OS] Synchronization (0) | 2023.04.06 |
| [OS] Threads (0) | 2023.04.02 |
| [OS] Processes (1) | 2023.03.29 |
| [OS] Operating System Structures (1) | 2023.03.20 |