Thread란 한 Process 안에서 실행되는 작업(Task)의 단위이다.
즉, Thread는 Process보다 작은 작업의 단위이다.
Process내엔 여러 개의 Thread가 존재할 수 있는데,
Thread는 Address Space에서 Stack 영역만 할당받고,
Process의 Code, Data, Heap 영역을 공유한다.
이 외에도, Register, Thread ID는 고유하게 할당받지만,
Open Files, Signal Handler, 작업환경( directory, user ID...) 등은 공유한다.
vs. Process
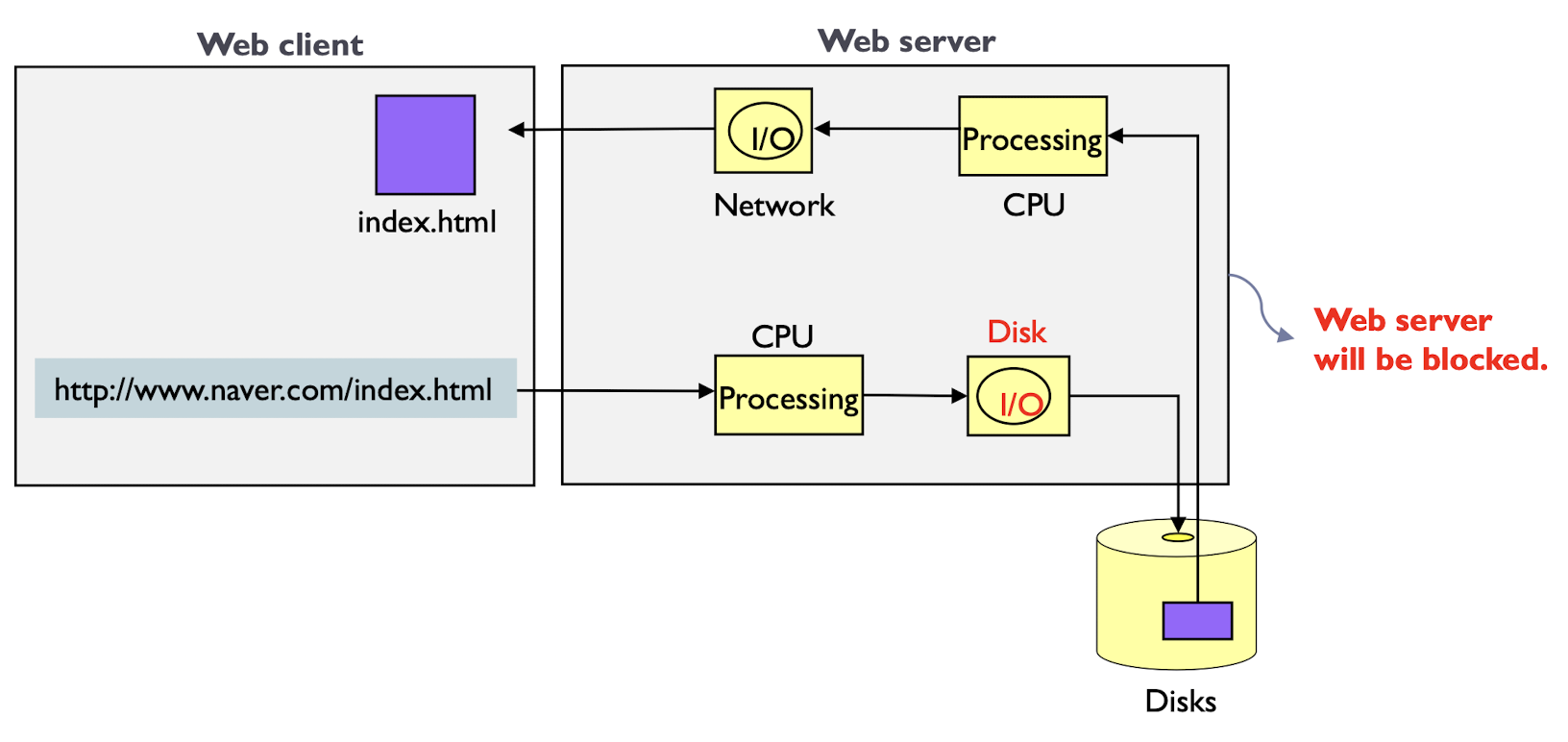
Web Page를 제공하는 프로그램이 있다 가정하자.
만약, I/O Operation이 수행된다 하면, 이 시간 동안 block 되고 다른 유저의 request를 처리하지 못할 것이다.
만약, 이를 위해 같은 Process를 여러개 생성한다면, Memory관점이나 시간관점에서 비효율적이다.
하지만, Thread로 이를 관리한다면, Code, Data, Heap 외에 여러 resource를 공유하기에 더욱 효율적이며,
생성에 소모되는 시간 역시 Process보다 Thread가 빠르다.
Multi Thread vs. Multi Process
Time-Shared System 혹은 Multi-Tasking에선
여러 Task를 번갈아 가며 수행하여, 유저에게 동시에 수행하는 것처럼 느끼도록 제공한다.
여기서 작업(Task)의 단위를 Process로 보게 되면 "Multi Process",
작업의 단위를 Thread로 보게 되면 "Multi Thread"가 된다.
Multi-Tasking에선 번갈아 가며 수행할 때, Context Switching이 발생한다.
Multi-Thread에선 여러 Resource를 공유하기 때문에,
Multi-Process보다 생성과 Context Switching의 오버헤드가 적다.
Multi-Core Programming
CPU는 Core, Cache 메모리, 컨트롤러 등 여러 부품으로 구성된다.
이중 "Core"는 각종 연산을 담당하는 CPU의 핵심 요소이다.
즉, Multi-Core는 코어가 여러개 있으므로, 한 번에 여러 개의 연산을 수행할 수 있다.
또한, "Processor"는 명령어들을 처리하기 위한 논리회로이며,
Control Unit과, ALU로 구성된다.
Device가 해야 할 일을 총 지휘하는 Processor를 "CPU",
CPU를 보조하는 Processor를 "Coprocessor",
소형 디바이스 혹은 PC에 있는 Processor를 "MicroProcessor"라 부른다.
하지만, 현대에서는 Processor와 CPU라는 용어를 비슷한 의미로 사용한다.
따라서, Multi-Processor란 Processor(CPU)가 여러 개 있다는 의미이며,
결론적으로 한번에 여러 개의 연산을 수행할 수 있다.
Multi-Core와 Multi-Processor는 결론적으로 동시에 여러 개의 연산을 병렬적으로 처리할 수 있게 해준다.
Concurrency vs. Parallelism
"Concurrency"(동시성)은 Multi-Tasking을 의미한다.

즉, 실질적으로 작업이 여러 개가 동시에 돌아가는 것이 아닌,
Context-Switching을 통해 여러 작업을 번갈아가며 수행하여, User에게 동시에 수행되는 것처럼 제공한다.
앞서 언급했듯이,
작업의 단위가 Thread의 경우에는 Multi-Thread
작업의 단위가 Process의 경우에는 Multi-Process라 부른다.
Multi-Thread의 경우에는, Context Switching의 오버헤드가 줄어들어 더욱 효율적이다.
반면, "Parallelism"(병렬성)은 Multi-Processor 혹은 Multi-Core를 통해
실질적으로 여러 작업이 병렬적으로 수행되는 것을 의미한다.
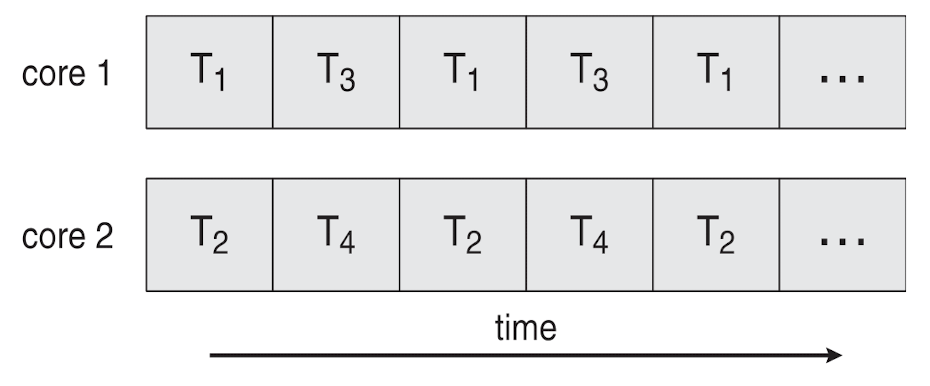
해당 그림에선, 여러 Core에서 작업을 병렬적으로 처리하면서,
각 Core에서는 Concurrency를 통해 작업을 처리한다.
User Threads vs. Kernel Threads
Thread는 누가 생성하냐에 따라, User Thread와 Kernel Thread로 구분할 수 있다.
User Threads는 User Mode에서 수행되는 Thread이다.
이는 Library에 의해 제공되며,
User-Level Threads Library에는 POSIX pthreads, Win32 threads, JAVA threads 등 이 있다.
이렇게, Library를 통해 생성된 User Threads는 OS가 알지 못한다.
Kernel Threads는 Kernel Mode에서 수행되는 Thread이다.
이는, OS에 의해 관리되며 제공된다.
OS에서 Thread지원하지 않는 경우
OS에서 Thread를 지원하지 않는 경우가 있는데,
해당 경우에는 Libirary를 통해 User Mode에서 Thread를 생성할 수 있다.
하지만, 앞서 언급했듯이 아래의 그림처럼 OS에서는 Thread의 존재를 알지 못하고 Process로 인식을 한다.
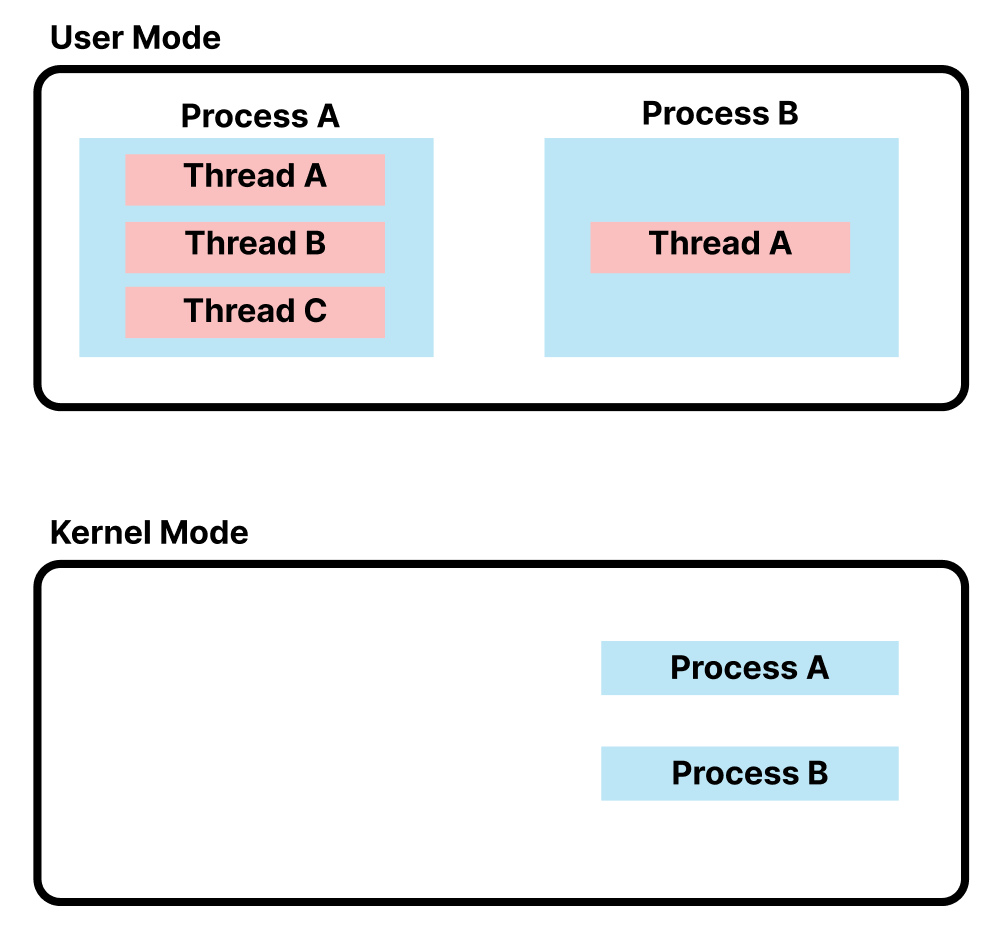
위와 같은 구조에선, Process 내에서 Thread가 바뀌게 되면,
OS입장에서는 작업이 변경되는 것이 아닌, 같은 작업 내에 다른 명령어만 실행하는 구조가 된다.
따라서, User Thread에선 Context Switching이 일어나지 않으며, 이로 인한 오버헤드가 발생하지 않는다.
반면, Process A의 Thread B에서
I/O Operation과 같은 Interrupt이 발생하면,
OS는 Thread의 존재를 알지 못하기 때문에,
해당 Thread만 Block 시키는 것이 아닌,
Process A가 Block 되게 되어, Process A내에 모든 Thread는 Block 된다.
OS에서 Thread를 지원하는 경우
OS에서 Thread를 지원하는 경우에는,
OS에서 제공하는 Thread를 사용하는 것과
User Thread를 생성하여 OS에서 제공하는 Thread와 매핑하는 방식이 있다.
우선, OS에서 제공하는 Thread를 직접 사용하는 경우에는
안정적이지만, User Mode에서 Kernel Mode로 계속 바꿔주어야 하기 때문에 성능의 저하가 발생한다.
반면, User Thread를 사용하는 경우엔, 안정성은 떨어지지만 성능의 저하는 발생하지 않는다.
User Thread를 사용하는 경우에는 Kernel Thread와 매핑하게 되는데,
어떻게 매핑하냐에 따라 여러 가지로 나뉘게 된다.
Many-to-One Model
이는 여러 개의 User Thread를 하나의 Kernel Thread에 매핑하는 방식이다.
이는 앞서 살펴본 OS에서 Thread를 지원하지 않았을 때처럼,
User Thread의 변경은 Context Switching이 발생하지 않지만,
하나의 User Thread에서 interrupt가 발생하면, 매핑된 다른 User Thread도 Block 된다.
One-to One Model
User Thread와 Kernel Thread가 1:1로 매핑되는 방식이다.
이는 Many-to-One Model에 비해 Concurrency는 향상될 수 있으나,
User Thread를 늘리면 Kernel Thread로 같이 늘어난다.
Kernel Thread의 생성은 오버헤드가 큰 작업이기에,
많은 User Thread의 생성은 성능 저하가 발생할 수 있다.
Many-to-Many Model
이는 여러 User Thread가 여러 Kernel Thread에 매핑되는 방식이다.
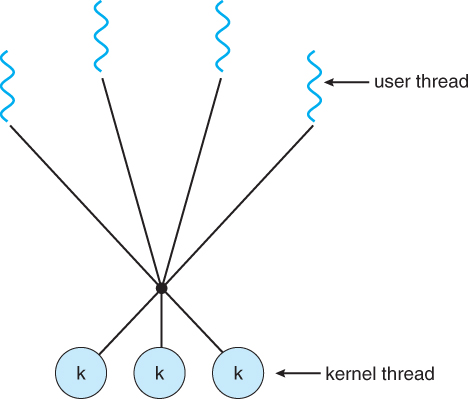
이는 User Thread에서의 I/O 작업을 통해 Interrupt가 발생하게 되어,
Kernel Thread가 Block 된다 하더라도,
다른 User Thread를 다른 Kernel Thread로 매핑하여 Block 상태에 빠지지 않고 작업을 이어 나갈 수 있다.
Linux Threads
Linux에서는 clone()이라는 System Call을 통해 Thread를 생성할 수 있다.
엄밀히 말하자면, Linux에선 Process와 Thread를 구분 짓지 않지만,
clone의 flag로 얼마나 자원을 sharing 할지 세팅하여 Thread처럼 만들 수 있다.
CLONE_FS: File-System 정보를 공유CLONSE_VM: Memory space를 공유CLONE_SIGHAND: Signal Handler를 공유CLONE_FILES: Open File들을 공유
clone(CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND, 0): Thread와 유사clone(CLOSE_SIGHAND, 0): Process와 유사
Reference
'CS > Operating System' 카테고리의 다른 글
| [OS] Synchronization (0) | 2023.04.06 |
|---|---|
| [OS] CPU Scheduling (0) | 2023.04.05 |
| [OS] Processes (1) | 2023.03.29 |
| [OS] Operating System Structures (1) | 2023.03.20 |
| [OS] Operating System (0) | 2023.03.12 |