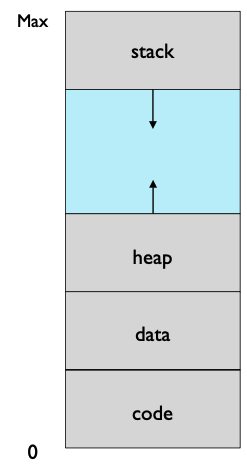
"Virtual Memory"란 Process전체가 Memory에 할당되지 않아도 실행시키도록 하는 메모리 관리 기법 중 하나이다.
즉 이를 통해, Process는 Memory Space보다 더 큰 가상 주소 공간을 할당할 수 있게 된다.
저번 포스팅에서 Physical Address와 Logical Address의 차이점을 비교하였다.
"Logical Address"는 CPU 입장에서의 주소이다.
Contiguous Allocation에선,
Process의 시작위치를 0으로 하는 상대 주소와 (Load Time Binding, Run Time Binding)
실제 Main Memory에서의 주소인 절대 주소가 (Compile Time Binding)
Logical Address가 될수 있다.
하지만, 연속적으로 할당되기 때문에 Logical Address와 Physical Address가 완전히 독립적이진 못한다.
반면 Uncontiguous Allocation에선,
Page와 Segmentation을 통해 Memory에서 연속적이지 않아도 실행이 가능했다.
이를 가능하게 하는것이 Virtual Memory이다.
즉, Logical Address는 Virtual Memory의 주소를 가리키게 된다.
이러한 주소들은 MMU를 통해 Main Memory상의 Physical Address로 Bindind된다.
즉, Logical Address와 Physical Address가 완전히 독립적일 수 있다.
이때 Logical(Virtual) Address의 집합을 "Virtual Memory"라 부른다.
정리하자면 Virtual Memory는 Process가 Physical Memory보다 큰 공간의 Logical Address를 갖도록 해주며,
Uncontiguous Allocation을 가능하게 하며,
Paging과 Segmentation이 Virtual Memory기법 중 하나이다.
Virtual Memory가 제공하는 기능은 다음과 같다.
- Memory Protection : Base Register와 Limit Register를 통해 범위 체크를 할 수 있다.
- Demand Paging(Segment)을 통해 Program의 크기가 Physical Memory보다 크더라도 실행시킬 수 있다.
Demand Paging
Program을 실행하기 위해, 한 번에 Main Memory에 올려야 한다면,
Program이 Physical Memory보다 큰 경우 실행할 수 없다.
하지만, 실제 Program을 실행할 때 사용하는 기능은 일부이다.
"Demand Paging"이란,
Disk의 Page를 필요할 때 Main Memory로 Load하는 방법이다.
만약 Main Memory의 공간이 다 찼다면, Swapping기법을 통해 Memory공간을 확보한다.
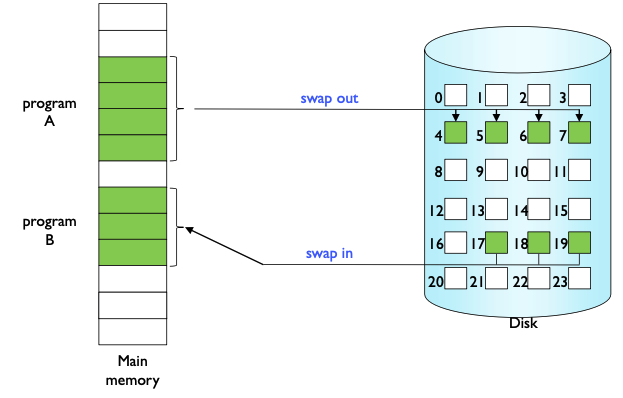
저번 포스팅에서 모든 Program은 Page단위로 나뉘게 되며,
프로그램 실행시에 필요한 Page만 Load하고,
이후에는 필요한 Page를 Load한다 하였다.
해당 개념이 Demand Paging이다.
더 정확히 애기하자면,
Page는 Virtual Memory기법 중 하나이며,
Virtual Memory는 Demanding Page기능을 제공한다.
예를 들어, FIFA Online이라는 게임은 30GB가 넘는다.
이는 RAM에 한 번에 올라가지 않는 크기임에도 PC에서 실행이 되는데,
이것은 Demand Paging을 통해 가능하다.
처음 실행 시 필요한 Page를 Load하고,
이적시장에 들어가면 해당 기능에 맞는 Page를 Load한다.
만약, Memory 공간이 부족하다면 Swapping을 통해
이전의 Page를 Disk로 Swap Out한다.
Page Fault
만약 접근하고자 하는 Page가 Page Table에 존재하는지 여부는 "Valid-Invalid Bit"를 통해 가능하다.
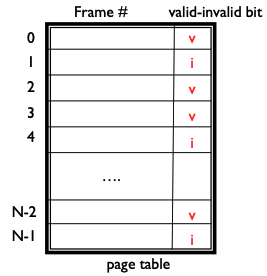
만약 Valid-Invalid Bit가 v라면 해당 Page가 Main Memory 위에 있다는 것을 의미하고,
i라면 Main Memory에 없거나, 잘못된 접근을 의미한다.
잘못된 접근은 Protection Violation과 범위를 벗어나는 Address 접근이 있다.
Valid-Invalid Bit가 i인 경우 Page Fault라 부른다.
Page Fault Handler
Page Fault가 발생하면 SW Intterupt가 발생하는데,
OS의 "Page Fault Handler"가 이를 처리하기 위해 호출된다.
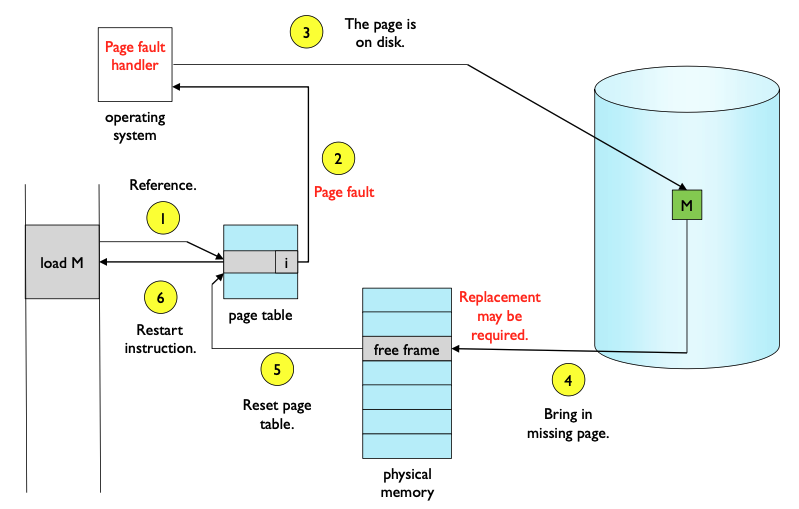
- 우선, Virutal Memory에서 요구하는 Page를 Page Table에서 탐색한다.
- Page를 찾으면, Valid-Invalid Bit를 확인한다.
- Valid-Invalid Bit가
v라면 Physical Memory로 이동한다.
- Valid-Invalid Bit가
i라면 Interrupt를 통해 OS에게 Page Fault를 알린다. - OS는 Page Fault Handler를 호출한다.
- 만약 Page Fault가 잘못된 접근이라면, Process를 강제종료한다.
- 잘못된 접근이 아니라면, Physical Memory로부터 비어있는 Frame을 할당받는다.
- 비어있는 Frame이 없다면, Main Memory의 Page 중 하나를 Swap-Out한다.
- 이후, 정해진 Frame으로 Load하는데, Disk로부터 Main Memory로의 이동은 오래 걸린다. 따라서, 이동(I/O Operation)이 완료될 때까지 Process는 Block(Waiting) State가 된다. 즉, PCB의 현재상태를 저장하고 CPU자원을 반납한다.
- Main Memory로 Load가 완료되면, Page Table의 Valid-Invalid Bit를
v로 설정하고, Process를 Ready Queue로 보낸다. - 이후 Dispatcher에 의해 CPU를 할당받는다면, PCB를 통해 복구하고 Page Fault가 발생했던 Instruction부터 다시 실행한다.
Effective Access Time (EAT)
Page Fault Rate를 알 수 있다면 Demand Paging의 성능을 계산할 수 있다.
Page Fault Rate를 0 ≤ $p$≤ 1.0 이라 가정하자.
EAT = ($1 - p$) X Memory Access Time + $p$ X Page Fault Service Time
이 된다.
Page Replacement
Page Fault가 발생하면, Disk에서 Main Memory로 왔다 갔다 해야 하기 때문에,
Overhead가 발생한다.
이러한 Overhead를 줄이는 방법은 Page Fault Rate를 줄이는 것이다.
Page Fault Rate를 줄이는데 있어서,
Memory의 Frame의 공간이 없을 때 "어떤 Page를 뺄 것인가"는 중요한 이슈이다.
만약, 뺀 Page가 다음에 또 쓰일 Page라면 Overhead가 발생하기 때문이다.
Page Replacement Algorithm은 "어떠한 Page를 뺄 것인가"를 결정한다.
이때 Disk로 Swap-Out되는 Page를 "Victim Page"라 부른다.
FIFO Page Replacement
가장 먼저 들어온 Page를 Swap-Out하는 알고리즘이다.
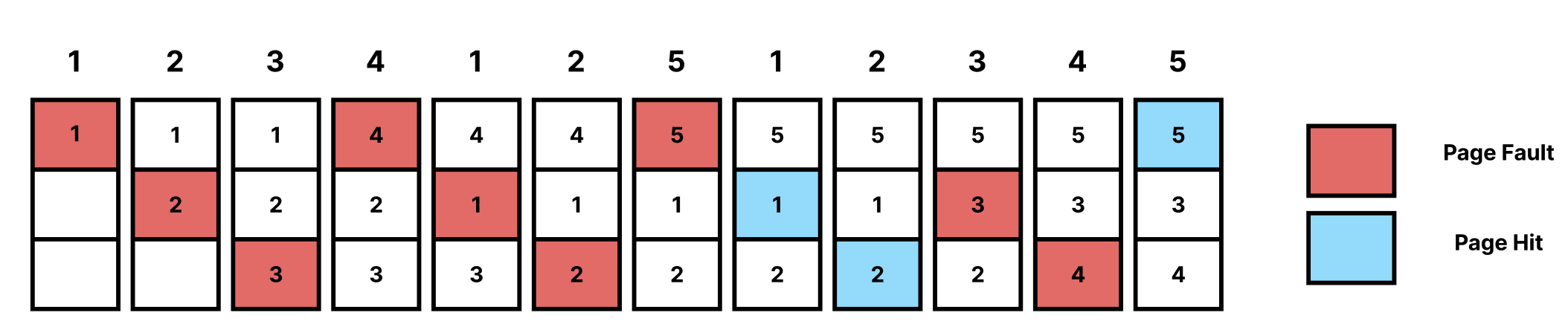
위의 그림에서 빨간색 부분은 Fage Fault가 발생한 부분이며, 파란색은 Page Hit를 의미한다.
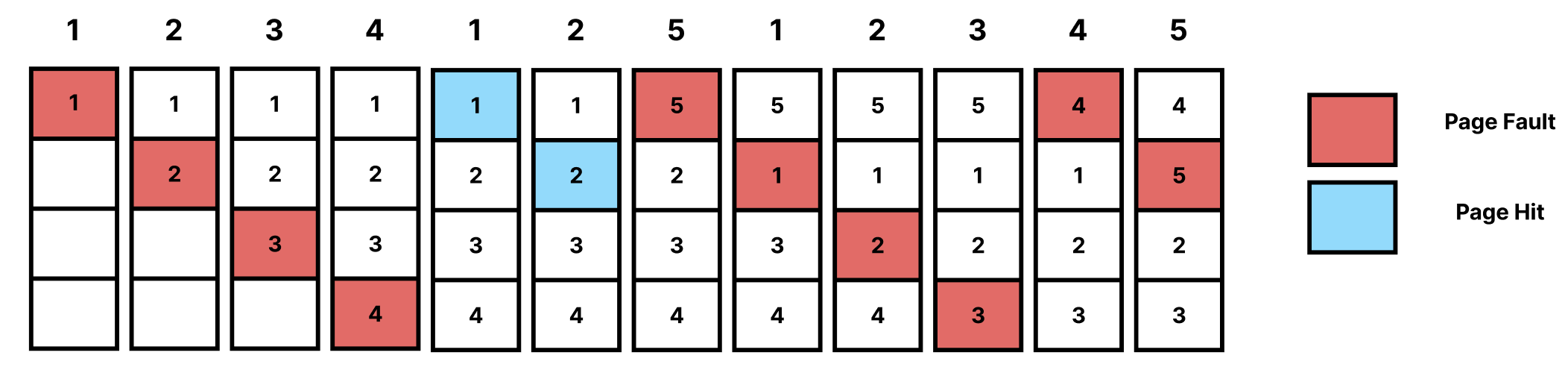
보통 Frame의 갯수가 많아지면 Page Fault비율은 감소한다.
하지만, 3개의 Frame을 사용했을 때는 9번의 Page Fault가,
4개의 Frame을 사용했을 때는 10번의 Page Fault가 발생한다.
이렇게 FIFO에선 분명 더 많은 Page Frame을 사용함에도 불구하고
Page Fault의 비율이 늘어나는 현상이 발생하는데,
이를 "Belady's Anomaly"라 부른다.
Optimal Page Replacement
앞으로 가장 오랫동안 사용하지 않을 Page를 교체하는 알고리즘이다.
가장 이상적으로 Page Fault의 비율이 가장 낮은 알고리즘이다.
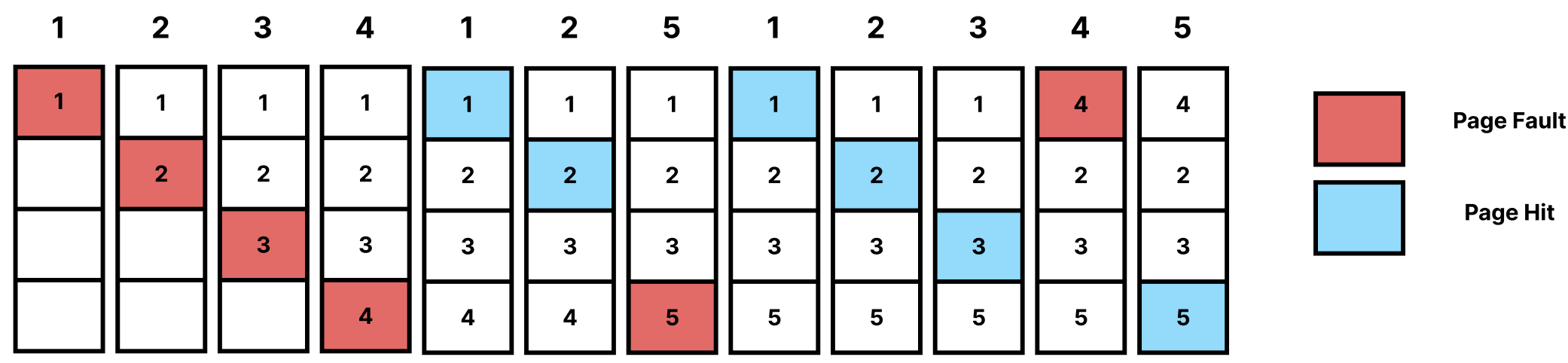
위의 그림을 더 자세하게 살펴보자.
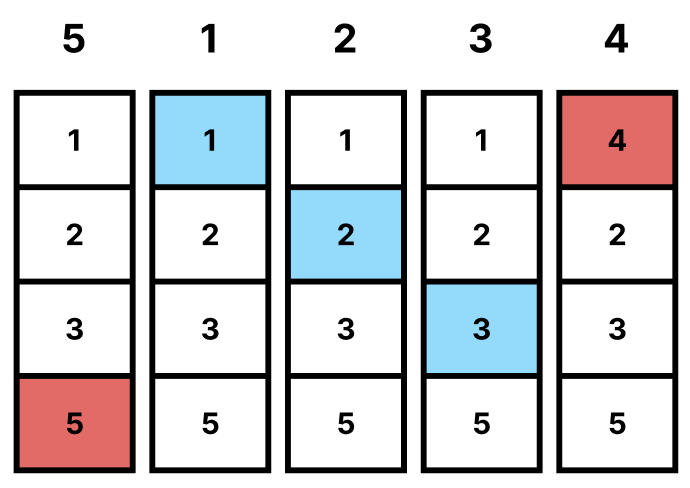
5인 Page가 필요할 때, Page Replacement가 일어나야 한다.
1, 2, 3, 4중 4가 가장 나중에 쓰이게 되므로 4와 교체가 일어난다.
CPU입장에서 미래에 쓰일 Page들을 모두 알아야 하기 때문에,
현실적으로는 구현이 불가능한 알고리즘이다.
LRU (Least Recently Used)
대부분의 프로그램에선 "Temporal Locality" 성질이 존재한다.
이는 Loop와 같이 최근에 참조된 Page가 미래에 다시 참조될 가능성이 높은 성질을 말한다.
이러한 성질에 따라, 가장 오래된 Page를 Swap-Out하는 것이 "LRU" 알고리즘이다.
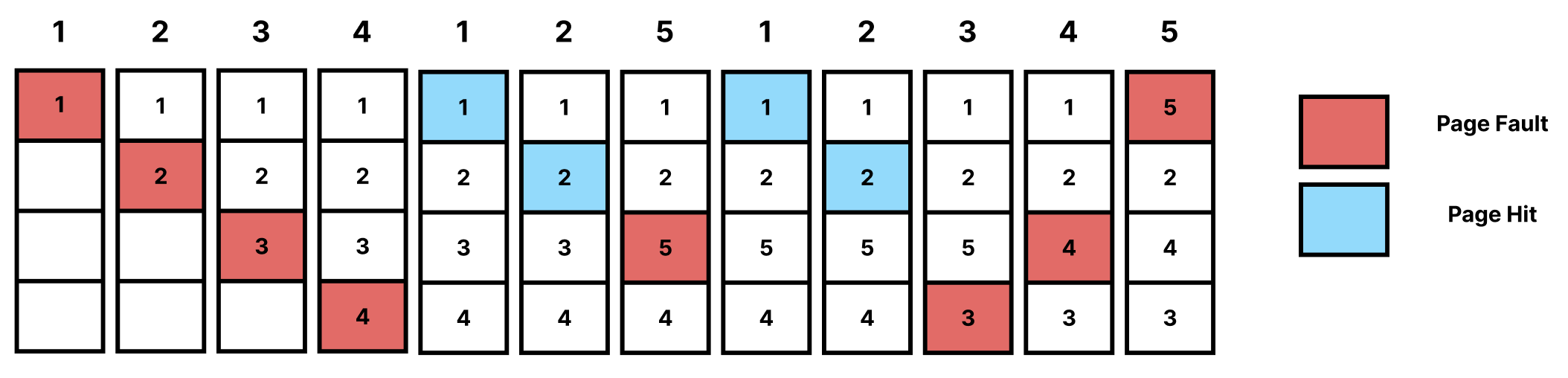
해당 알고리즘에선 8번의 Page Fault가 발생한다.
LRU는 Reference Time을 각 Page마다 기록해야 되기 때문에,
HW적 지원이 필요하다.
HW적 지원으로는 Counter와 Stack 두 가지 종류가 있다.
Counter Implementation
각 Page는 Counter가 존재한다.
새로운 Page가 요청될 때마다, Clock의 값이 1 증가한고,
요청된 Page는 Clock의 값을 Page의 Counter로 복사한다.
빈 Frame이 없어 Page를 교체해야 할 때는
Counter값이 가장 작은 값을 가진 Page를 Swap-Out한다.
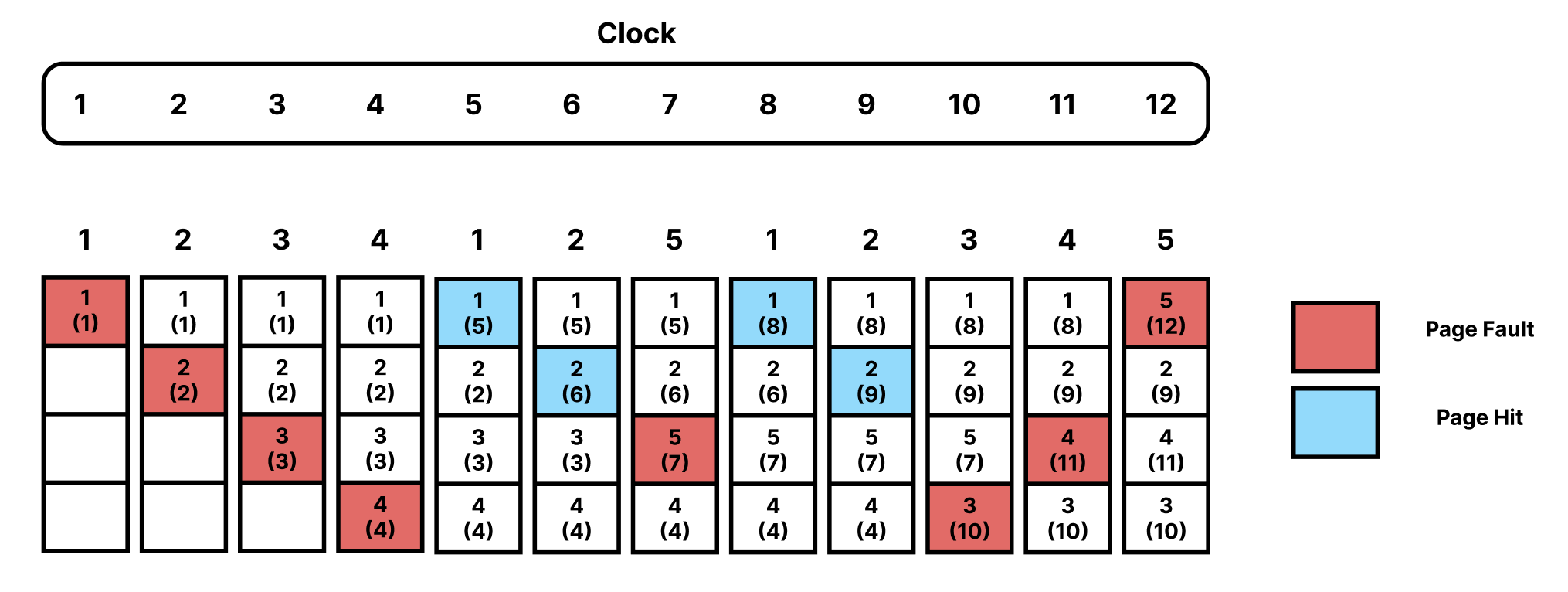
하지만, 해당 방법은 매번 Counter의 값을 탐색해야 하기 때문에 Overhead가 발생하며,
Frame이 많아질수록 Overhead는 같이 늘어가게 된다.
Stack Implementation
Reference Stack을 만들어
Page가 사용될 때마다 Stack의 Top에 두는 방법이다.
즉, Stack의 Bottom에 있는 Page가 교체의 대상이 된다.
해당 방법은 탐색을 통한 Overhead는 발생하지 않는다.
LRU Approximation Algorithms - Second Chance Page Replacement
HW적 지원이 없는 경우, LRU 알고리즘을 사용하지 못한다.
많은 시스템들은 Page Table의 Reference Bit를 통해
LRU에 근사한 알고리즘을 지원한다.
그중 하나가 Second Chance 알고리즘이다.
Page Table의 Reference Bit은 기본적으로 0으로 세팅되고,
Page가 Reference된다면 1로 세팅된다.
하지만, Reference된 순서는 알지 못한다.
Second Chance 알고리즘은 기본적으로 FIFO알고리즘에 기반을 둔다.
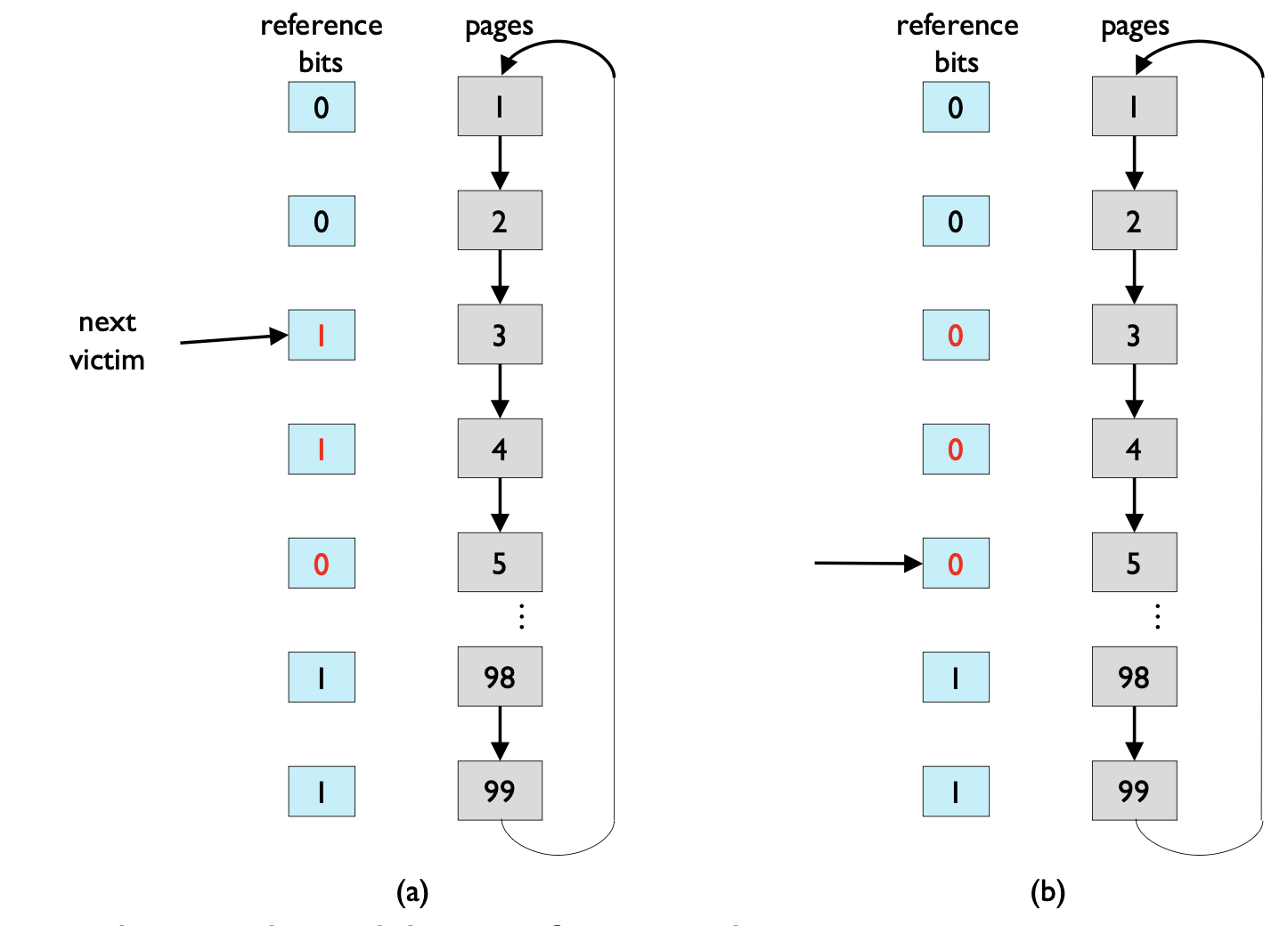
검사할 Page를 가리키는 포인터가 존재하며, FIFO에 따라 Victim(교체될 Page)를 찾는다.
만약, 현재 Victim의 Reference Bit가 1이라면,
Reference Bit을 0으로 바꾼 후 교체하지 않는다.
즉, 한번 더 기회를 준다.
만약 모든 Frame내의 Page의 Reference Bit가 1이라면,
한번 순회하는 과정에서 모두 Reference Bit를 0으로 바꿔 주었기 때문에,
FIFO처럼 작동한다.
다시 한번 기회를 줌으로써, 가장 최근에 참조된 Page가 교체되는 것을 어느 정도 막을 수 있게 된다.
Counting Algorithm
"Counting 알고리즘"은 발생빈도를 보고 교체하는 알고리즘이다.
Counting 알고리즘에는 크게 2가지가 있다.
- LFU(Least Frequently Used) : 가장 조금 사용된 Page가 교체된다.
- MFU(Most Frequently Used) : 가장 많이 사용된 Page가 교체된다.
해당 알고리즘은 사용빈도를 구해주는 추가적인 support가 필요하다.
Allocation
Process마다 크기가 다르기 때문에 "얼만큼의 Frame을 할당할지"에 대한 이슈가 생긴다.
Allocation Algorithm
Fixed Allocation
Fixed Allocation은 크게 2가지로 나뉜다.
모든 Process마다 같은 수의 Frame을 할당하는 "Equal Allocation"과
Process의 Size의 비율대로 나누는 "Proportional Allocation"이 있다.
Priority Allocation
Priority Allocation은 Proportional Allocatoin방식을 사용하는데,
Size가 아닌 우선순위에 따라 나눈다.
Global vs. Local Replacement
지금까지 여러 Page Replacement에 대해 알아보았지만,
어떤 Process의 Page인지 신경 쓰지 않고 Replacement를 진행했다.
실제로 같은 Process의 Page라면 쫓아내지 않는 것이 유리하지만, 단점 역시 존재한다.
따라서, 어떻게 Victim Page를 선택할지에 대한 이슈가 생긴다.
여러 Process의 Page가 Memory에 올라와 있을 때, Page Replacement는 크게 2가지로 나뉜다.
Global Replacement
한 Process는 Memory내의 모든 지역에서 Victim을 선택할 수 있다.
즉, A Process가 B Process의 Page를 교체할 수 있게 된다.
따라서, 자신의 Page Fault Rate를 Control할 수 없다는 단점이 있다.
Local Replacement
Allocation Algorithm을 통해 자신이 속한 Frame 영역 내에서만 Victim을 선택할 수 있다.
이는 자신의 Page Fault Rate를 Control할 수 있게 되지만,
어떤 Process에선 Page Fault가 많이 일어나고, 다른 Process에선 Frame이 남게 되는 현상이 발생할 수 있다.
Thrashing
메모리 공간 부족으로 인해,
Process가 집중적으로 사용하는 Page가 Memory에 한 번에 Load되지 못하는 경우
Page Fault 비율은 높아지게 된다.
Page Fault가 일어나면 Process는
Page Fault Handler에 의해
Disk로 부터 Main Memory로 Page를 Load하는 I/O작업이 필요하다.
해당 I/O작업 동안 Process는 Wait상태가 되며, CPU 사용을 안 하게 된다.
이러한 Process가 많아질수록 CPU Utilization 감소로 이어진다.
CPU Utilization이 감소되면 Schedular는 더 많은 Process를 할당하게 되고,
이는 각 Process의 Page간의 메모리 경쟁이 더욱 심해지게 되며,
Page Fault가 더 많이 일어나 결론적으로는 CPU Utilization 감소가 반복되는 악순환이 발생한다.
이러한 현상을 Thrashing이라 말한다.
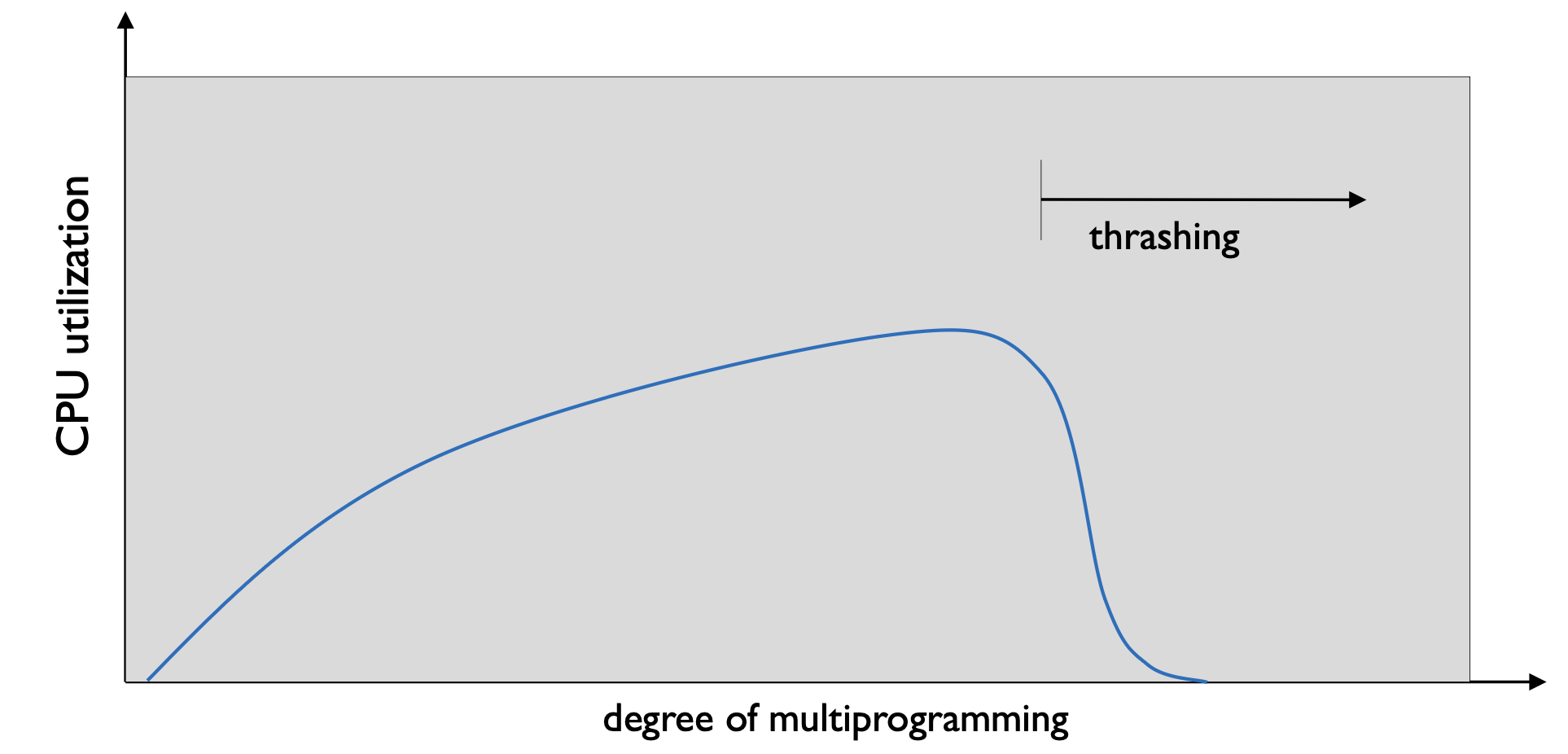
위의 그림에서 Program이 증가할수록 특정 지점부터
CPU Utlization이 떨어지는데 이 부분을 Thrashing이라 부른다.
Process는 Locality에 의해 일정시간 동안
특정 Page를 집중적으로 Reference한다.
예를 들어, for문이 진행되는 동안 특정 Page가 반복적으로 Reference된다.
따라서, 할당된 모든 Process의 Locality가 Main Memory보다 크기 때문에,
Page Fault 비율이 많아져 Trashing현상이 발생한다.
Working-set Model
"Working-set Model"은 Thrashing을 방지하는 모델로,
Locality집합이 동시에 메모리에 올라가는 것을 보장하는 모델이다.
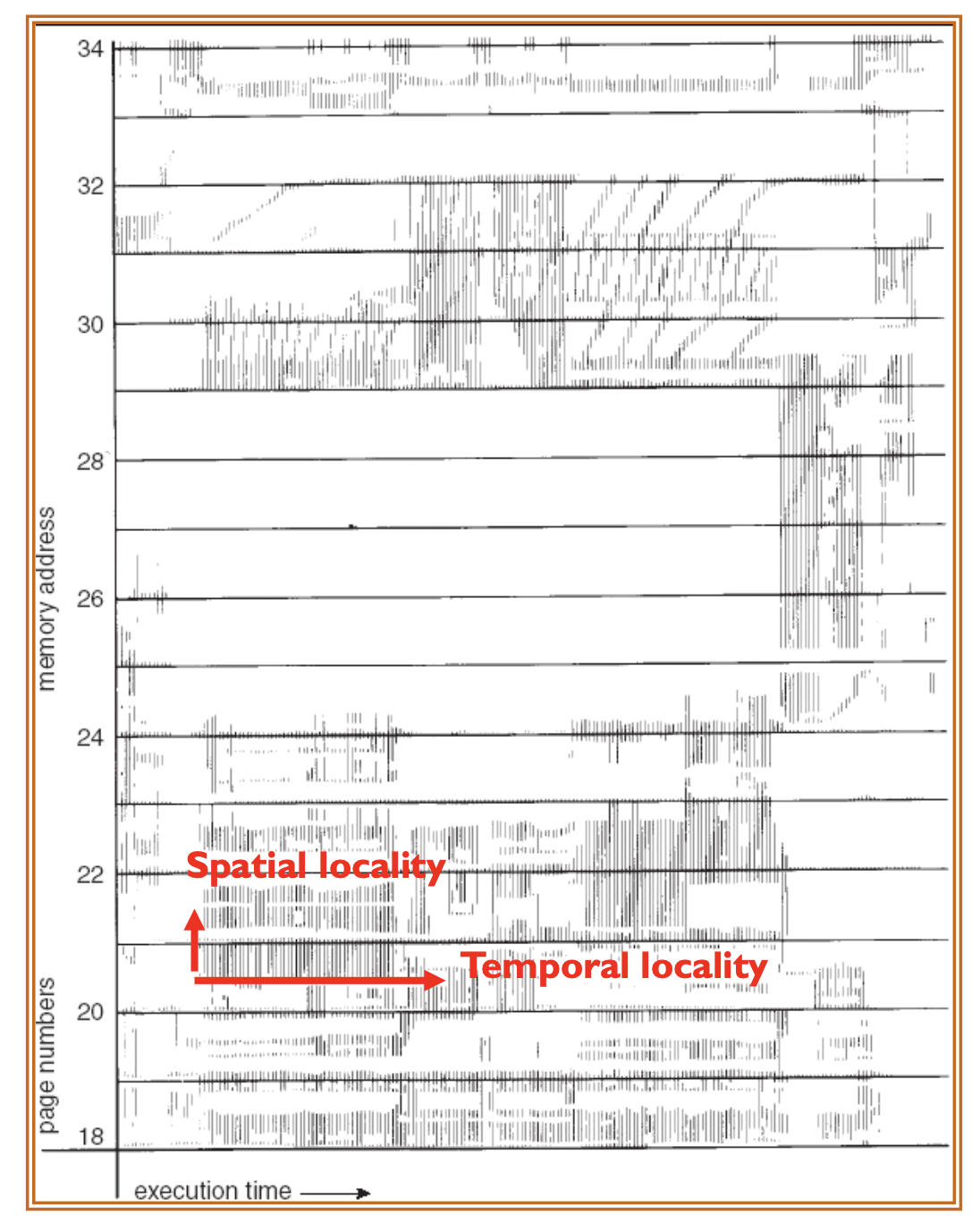
"Spatial Locality"는 Reference된 주변 영역을 의미하고,
"Temporal Locality"는 Reference된 메모리 주소를 의미한다.
Working-set Model에선,
Locality집합을 "Working Set Window(Δ)" 로 나타낸다.
Locality를 고려한 Page의 개수가 3이라면, Δ은 3이 된다.
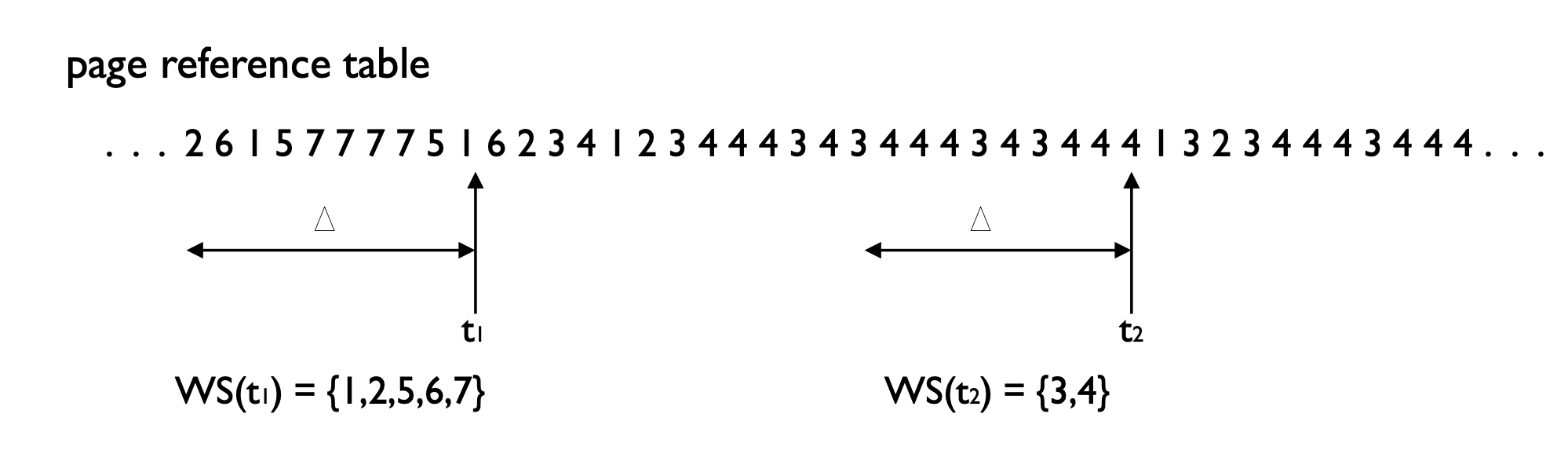
해당 그림에선 Δ을 10으로 설정하였고,
$t_1$ 시점을 기준으로는 1,2,5,6,7이 Locality 집합이 된다.
또한 $t_2$시점을 기준으로는 3,4가 Locality 집합이 된다.
Working Set Window가 너무 크거나 작으면, Locality를 잘 반영하지 못하기 때문에,
적절한 값이 필요하다.
위와 같이 "Working Set"은 Locality를 기반으로
특정 Process에서 Page Fault가 잘 발생하지 않도록 해준다.
만약, Trashing이 발생한 경우,
(Process $P_i$에서 Working Set을 $WSS_i$라 가정하자.)
즉, $WSS_i$의 합이 Memory보다 큰 경우,
한 Process를 suspend시킨다.
References
Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 9th』
'CS > Operating System' 카테고리의 다른 글
| [OS] I/O Systems (0) | 2023.05.16 |
|---|---|
| [OS] Mass-Storage Structure (0) | 2023.05.15 |
| [OS] Main Memory(2) - Memory Allocation (1) | 2023.05.11 |
| [OS] Main Memory (1) (1) | 2023.05.09 |
| [OS] DeadLock (1) | 2023.04.29 |